Variational Inference by Implementation
A gentle introduction to variational inference applied to Bayesian logistic regressions with accompanying PyTorch implementation.
Introduction
The most common problem that one faces in a Bayesian workflow is computing the posterior distribution. Markov chain Monte-Carlo (MCMC) offers one solution to this issues, but variational inference (VI) is an appealing alternative. In contract to MCMC, VI seeks to approximate the intractable posterior distribution by optimising the parameters of a tractable parametric variational distribution such that the distance between the variational distribution and the true posterior is minimised.
By virtue of being an optimisation-based approach, VI can offer several advantages over MCMC:
- It scales naturally to large datasets using stochastic gradient methods.
- It can leverage GPUs for more efficient computations.
- It provides explicit control over the complexity–accuracy trade-off through the choice of variational family.
The cost of these benefits is an approximation. Unlike MCMC, there are no guarantees that VI will eventually return the true posterior. This is primarily driven by the fact that we, as the practitioner, are forced to choose the family of distributions $\mathcal{Q}$ that our variational distribution is a member of. Oftentimes, for computational convenience, $\mathcal{Q}$ is chosen to be the family of (multivariate) Gaussian. Therefore, unless the true posterior is itself a Gaussian, then there is little chance that our variational distribution will ever become equivalent to the true posterior.
Mathematical Details
For an observed dataset $\mathcal{D}$ and parameters $\theta$, our posterior may be written as
$$p(\theta \mid \mathcal{D}) = \frac{p(\mathcal{D}\mid\theta)p(\theta)}{p(\mathcal{D})}.$$Letting the $\mathcal{Q}$, the variational family, be the set of multivariate Gaussian, we write a single variational distribution be written as
$$q_\lambda(\theta) = \mathcal{N}(\theta \mid \mu, \Sigma)$$where $\lambda$ is the variational distribution’s parameters.
To identify the optimal variational approximation $q^{\star}$, we seek to minimise
$$\mathrm{KL}\big(q_\lambda(\theta)\mid\mid p(\theta\mid\mathcal{D})\big),$$to yield the objective
$$q^{\star} = \arg\min_{q\in\mathcal{Q}}\mathrm{KL}\big(q_\lambda(\theta)\mid\mid p(\theta\mid\mathcal{D})\big).$$where $\mathrm{KL}$ denotes the Kullback-Leibler divergence (KLD).
Unfortunately, computing the KLD from the variational distribution to the true posterior is intractable. We are, therefore, required to reformulate the objective into a lower bound by rearranging, expanding, and bounding via Jensen’s inequality. A full derivation is given in Variational Inference from Scratch. The bound is known as the evidence lower bound (ELBO), and we write it as
$$\operatorname{ELBO} = \mathbb{E}_{q}\left[\log p(\mathcal{D} \mid \theta) \right] - \mathrm{KL}(q_\lambda(\theta) \mid\mid p(\theta)).$$The ELBO consists of two terms. The first, the expected log-likelihood, encourages the variational distribution to explain the observed data. The second term is the Kullback-Leibler divergence between the variational distribution and the prior, which acts as a regulariser. Our objective is to maximise the ELBO with respect to the variational parameters $\lambda$.
We shall now proceed to implement this routine.
| |
Show plotting code
| |
Implementation
Goal
Our goal in this notebook is to use VI to approximate the posterior of a Bayesian logistic regression model.
Core Structures
In the first stage of our implementation, we shall define the core components for our VI algorithm. This includes the variational distribution itself, a function to compute the KL divergence to the prior, and a function to compute the ELBO, our objective function.
The following code defines:
MeanFieldGaussian: A class for our mean-field variational distribution. It uses the reparameterisation trick for sampling and asoftplustransformation to ensure positive standard deviations.gaussian_kl_meanfield: A function for the analytical computation of the KL divergence between our variational distribution and the Gaussian prior.elbo_logistic_regression: A function that computes a Monte Carlo estimate of the ELBO. It combines the expected log-likelihood of the data with the KL divergence term.
| |
Data Prep
To test our implementation, we will use a synthetic dataset generated by the make_moons function from scikit-learn. To enable our logistic regression model to learn the non-linear decision boundary, we will augment the original 2D features with polynomial terms (e.g., $x_1^2, x_2^2, x_1x_2$). This transformation maps the data into a higher-dimensional space where a linear separation for the moons data becomes possible.
| |
Training
Now we are ready to train our model. The training process involves optimising the parameters of the variational distribution—its mean and standard deviation—to maximise the ELBO.
We use the Adam optimiser for this task. In each iteration of the training loop, we iterate the following steps:
- Calculate a stochastic estimate of the ELBO using a number of samples from the variational distribution.
- Compute the gradients of the negative ELBO with respect to the variational parameters. We use the negative ELBO because optimisers in PyTorch perform minimisation.
- Perform a gradient-step update of the variational parameters.
| |
Visualising Predictions
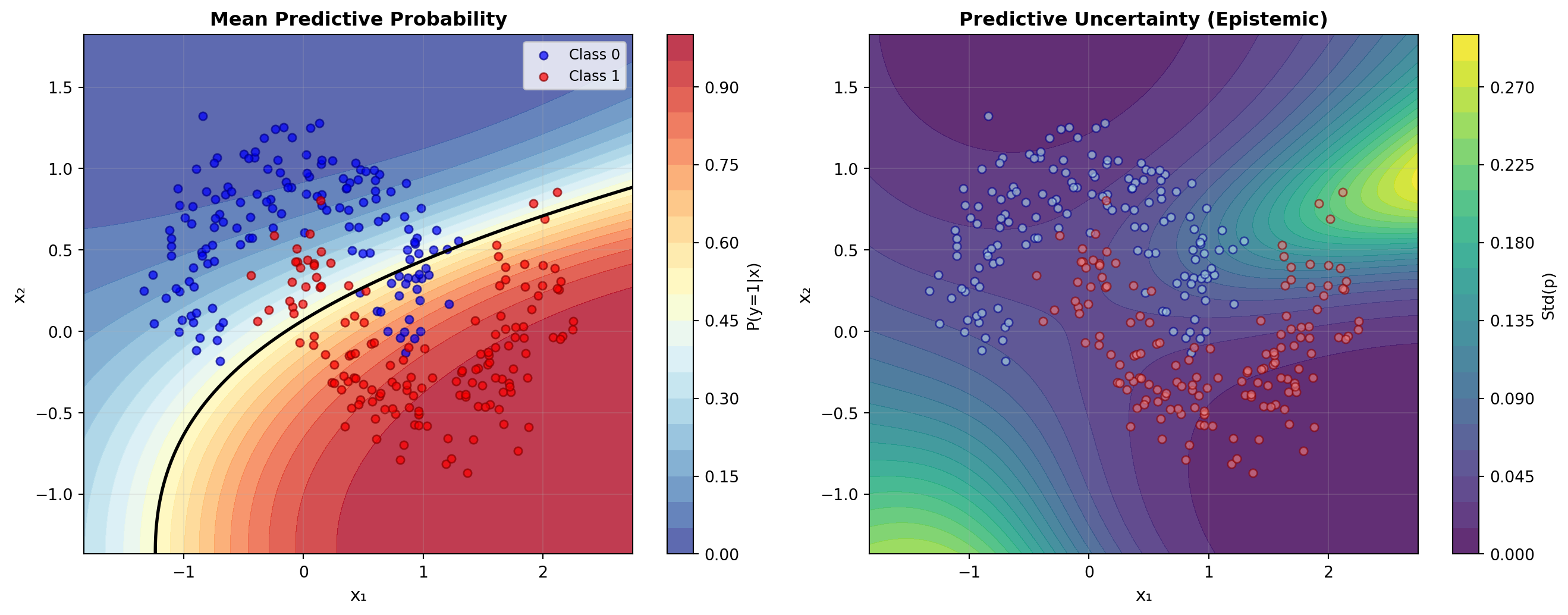
After training, our variational_dist provides an approximation to the posterior distribution over the model’s parameters. A key advantage of the Bayesian approach is the ability to quantify uncertainty, and we can now use this posterior approximation to make predictions that capture this.
To do this, we create a grid of points across the input space. For each point, we draw multiple samples of the parameters from our trained variational distribution. Each parameter sample defines a different logistic regression model and, therefore, gives a different prediction. The distribution of these predictions for a single point tells us about the model’s uncertainty at that location.
The final plot visualises both the model’s predictions and its uncertainty. We show the mean predictive probability, which is the average of the predictions across all parameter samples and represents the model’s effective decision boundary. Alongside this, we show the predictive uncertainty, calculated as the standard deviation of the predictions. This standard deviation is a measure of epistemic uncertainty—uncertainty in the model’s parameters—and we expect it to be higher in regions with little data.
| |